이미지 분류가 어려운 이유
- viewpoint variation
- illumination
- deformation
- occlusion
- background clutter ( cascade방식으로 처리 함)
고전적인 분류 방법들
- template based approach(포즈, scale 변화에 취약함)
- feature-based approach (edge, curve등을 활용)
- data-driven approach (feature descriptor와 classifier, svm등을 결합하여 사용)
** feature descriptor: Histogram of Oriented gradients (HOG)
** nearest neighbor도 사용할 수 있는데, class가 많아지면 성능이 낮아짐
(시험은 기존에는 어떻게 했는지에 대해서 파악하는걸로)
DNN과 차이가 있다면, feature 추출하는 방법과 classifier(분류기)가 합쳐졌음
어떤 feature를 사용할지 전에는 사람이 선택했다면 (feature engineering)
이제는 network가 자동으로 의사결정 함.
Histogram of Oriented gradients (HOG)
이미지의 전체적인 밝기가 변하더라도 gradient orientation은 변하지 않음
(gradient 크기는 변할 수 있음)
이미지의 전체적 윤곽을 gradient orientation통해 알 수 있음

분류기에 중요한 역할을 하는 orientation에 weight를 줘서 강조하게 되면
위와 같은 이미지를 확인할 수 있음
KNN
KNN: K개(홀수)의 이웃 데이터를 참고하여 분류하는 것
거리를 연산하는 계산이 복잡하므로
미리 partition을 설정해놓음
위와 같이 partition을 먼저 설정해놓음
CIFAR10 데이터를 사용해서 분류하는 학습으로 유명함
거리계산시에는 아래와 같은 2가지 방법을 사용할 수있음
K를 점점 더 크게 증가시킬 수록 어느정도 성능은 향상되나
다른 알고리즘에 비해서는 좋지 않음
현재는 4개만 맞았는데, K를 증가시키면 향상된 성능을 얻을 수 있음
추가로, RANK1박스만 보는 것이 아니라, RANK5까지 맞는 것이 있는지 본다면
역시 성능이 향상된 결과를 볼 수 있음
Neural Network (NN)
activation함수를 쓰는 이유:
변화량을 계산할 때, activation함수가 미분 가능하며 모든 구간에서 연속이 가능한것이 중요했음
→ sigmoid, tanh함수 사용
→ vanishing gradient 이슈발생
→ ReLU사용
→ 음수영역에대해서도 약간의 기울기를 준 것이 더 성능이 좋음
→ Leaky ReLU
Shallow에서는 하나의 layer가 모든 task를 수행하는 반면에
dnn에서는 각각의 layer각 각 task를 수행함
(성별 분류, 헤어길이 분류 등을 각 layer에서 나눠서 수행함)
→ 성능이 더 좋아짐(modular하게 분류함)
** GAN모델 같은 경우 새로운 데이터를 생성(변형)하는 데에 사용할 수 있음
(Generative Adversarial networks)
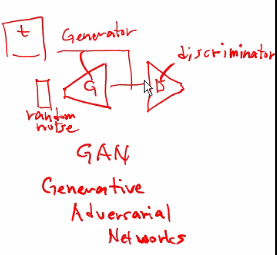
CNN
특히 이미지데이터의 경우, 많은 양의 pixel을 처리해야함
그때 CNN을 사용함
차이점 1. local connectivity
DNN은 fully connected라 연산량이 많지만 CNN은 각 뉴런을 input region에만 연결 (convolution)
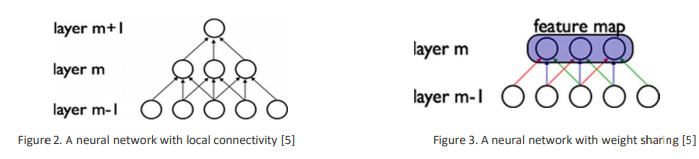
차이점2. Weight sharing
–Convolution layer의 weight의 개수를 조절하기 위해 사용됨
– 만약 이미지의 특정 위치에서 가로 edge를 검출하는 것이 중요했다면,
이미지의 다른 위치에서도 같은 특성이 중요할 수있다
차이점3. DNN은 weight를 학습하지만, CNN은 필터를 학습시켜나감
CNN구조 및 구성요소
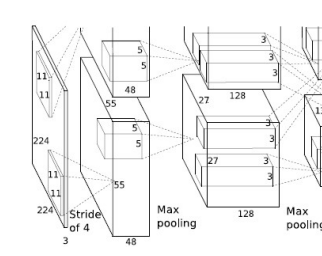
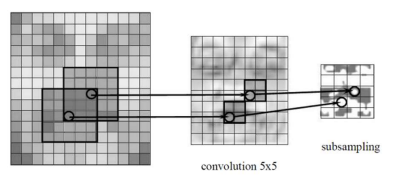
feature가 어느위치에 존재하냐보다는, feature가 활성화 되는지가 중요함
filter를 상하좌우 반전시켜서 적용(overlap)하면 convolution,
그대로 적용하면 correlation임
** padding을 하지않으면 feature map의 크기가 줄어듬
CNN Architecture: Pooling Layers을 사용함
• Translational Invariance을 얻을 수 있음
– Output remains the same even if feature is moved a little
• Reduce the size of feature map
• Different ways to implement
– Max Pooling most effective in practice
CNN Architecture: Fully connected layer
Fully connected layer를 가장 마지막에 추가해 줌
Training Neural Network
- Backpropagation Process
에러를 역전파시키는 과정에서 w를 update시킴
w= w+delta(w)
• When to update weights?
– Online Mode : after every training sample (보통 여러 epoch에 걸쳐 학습하게 됨)
– Batch Mode : after all training samples
참고하기
'IT > 영상처리분석' 카테고리의 다른 글
| Face recognition (0) | 2022.05.30 |
|---|---|
| Face Detection (0) | 2022.05.23 |
| 여러 종류의 Feature descriptor (0) | 2022.05.16 |
| keypoint detection - Harris, SIFT, SURF, LIFT (0) | 2022.04.18 |
| Line & Ellipse detection (0) | 2022.04.17 |