The quadtree
: 공간을 반복적으로 4등분해 나가는 기법
- Quadrant’s name : NW, NE, SW and SE
- 각각의 Quadrant는 하나의 disk page와 mapping이 됨

quadtree는 depth가 다름
** image indexing 할 때 주로 많이 사용
** Quadtree의 단점: 데이터들이 한쪽영역에 몰려있을 경우 트리의 balance가 깨짐
The quadtree에서의 point query

** oid는 상세한 정보까지 다 가지고 있는 indexing 방법임
1. 처음에 point의 위치를 보고 a, b, c, d 중 어느 가지로 내려갈지를 정함
2. 그 다음 x, y, z, t 중에 어느 가지로 내려갈지 정함
3. 그 다음 5, 14, 6 중 어느것이 p를 포함하고있는지 파악함
The quadtree에서의 rectangle 추가

The quadtree 단점
- data가 balance가 안되는 편향된 트리가 발생하는 경우, 성능이 좋지 않음
- page용량이 100이라고 할 때, child tree가 항상 4개로 고정되어있어 나머지 96개는 낭비가 됨
- High duplication rate
- map a quadtree to disk pages is not easy
total order vs. partial order
total order: 임의의 두 수를 뽑더라도 대소를 비교할 수 있는 것
partial order: 순서가 부분적으로는 있지만, 전체적인 것에서는 없는 경우
eg) 직장에서의 직위 체계는 partial order
상사와의 관계는 대소가 비교가 되지만, 직장동료 간에는 안됨
Space-filling curve
1. Z-order 사용 방법
공간을 split하여 임의적으로 순서를 정함
그러므로 대소를 비교할 수 있음

위 와 같은 좌표데이터에서 B, C점의 크기 비교는 불가능 함
아래와 같이 z-order를 사용하여 순서를 정할 수 있음

특징 : 하나의 공간에서는 하나의 label만 mapping 할 수 있음
(각각에 cell에 대응되는 object이 하나만 나올 때 까지 계속 쪼갬)
lexicographical order: 사전 정렬식 방법
3.2 < 3.3.1
2. Hilbert curve
Z order에서 0과 가까운 것은 1만이지만
(공간적으로 멀리 떨어져 있는 것을 가깝다고 인식함)
Hilbert curve에서는 0과 가까운 것이 1과 2임
(실제 공간을 반영함)

여기서 Z-order는 파란점은 가깝다고 인식하고
빨간점은 멀다고 인식 함
단, hilbert curve의 단점
가까운데 멀다고 인식하는 것은 해결이 여전히 안됨
또한 계산하기 위해 시간이 많이 걸림
여전히 hilbert curve에서도 두 빨간점은 멀다고 인식함
** 현실 오라클에서는 그래도 z-order를 사용함
(왜냐하면 심플하게 구할 수 있기 때문)
Z-order에서의 Z-value

z-value는 이진수의 값으로 계산 함
The Linear Quadtree
Z-order를 활용한 quadtree labeling

각 쪼개진 영역에 00, 01, 300등의 label을 맵핑 시켜 줌

위 처럼 tree를 z-order로 정리한 것이 Linear quadtree임
00, 300등은 mbb임
degree 3까지 쪼개진 것임(300과 같이 3개의 digit으로 나타낼 수 있으므로)
→ the entries [mbb, oid] have been assigned to a quadtree leaf
단점. 여전히 중복이 발생함(파란색 c들…)
Point query algorithm with a linear quadtree

maxinf는 tree에서 검색하는 함수로,
320보다 같거나 작은 것 중 가장 큰 entry를 return해주는 함수
여기서 p는 3.2.0로 표현 됨 (3-degree이므로 32 이지만 320으로 표현함)
여기서 또 320는 31보다 크므로 가장 오른쪽의 leaf로 따라내려가서
320보다 같거나 작은(33은 크니까 제외) 32의 entity중
p를 포함하는 mbb를 return(c)
Window query algorithm with a linear quadtree
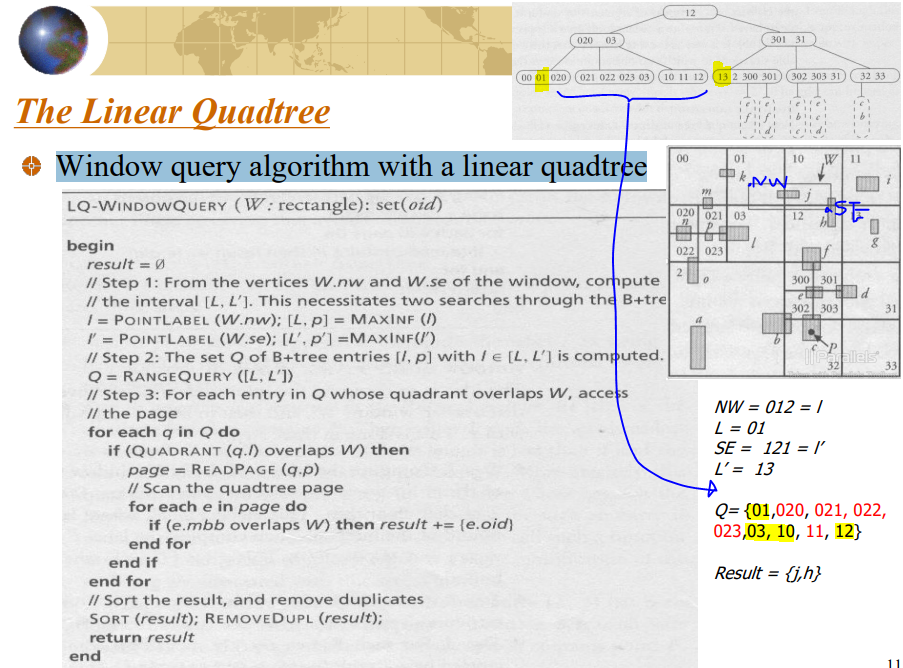
{01: k, j / 03: l / 10: j, h / 12: h,f} 중에서 window와 겹치는 것은 j, h 만 겹침 = result
result = { j, j, h, h } 에서 sort 후 중복을 제거하면 {j, h} 만
The Linear Quadtree 분석
point query에서 I/O는 depth + 1만큼의 I/O발생함
** +1은 하나를 갖고와야 되니까

windown query에서는 양 끝값에 대해 탐색해야 되므로 2d
그 사이의 interval k만큼 scan 해야하므로 +k
'IT > 공간정보처리시스템' 카테고리의 다른 글
| R-tree (0) | 2022.10.22 |
|---|---|
| z-ordering Tree (0) | 2022.10.13 |
| Spatial Access Methods 1 - Space-Driven Structure (3) | 2022.10.01 |
| Spatial DB system 0921 (1) | 2022.09.28 |
| Spatial Concepts and Data Models (0) | 2022.09.18 |