기존 indexing의 문제점
high dimensional data에서는 기존의 indexing 기법이 잘 적용되지 않음
비슷한 데이터의 grouping이 힘들게 됨
→ 겹치는 데이터가 많아짐
→ 차원의 저주
M-tree(Metric indexing)
직접 grouping하는 것이 아니라,
거리를 계산하여 거리기준으로 grouping 하는 것
(distance based indexing)
따라서 차원에 대해 independent한 indexing을 설계 할 수 있음
metric space
metric space에 존재한다고 하려면 아래 조건을 만족해야함

도로망 같은 경우는 metric space의 조건을 만족하지 않음

A보다 B도로가 더 길 수 있음
M-tree 특징
차원의 저주에 dependent 하지 않음
traiangular inequality를 만족함
metric space에 있다고 가정함
용어정리
gound object= leaf node 에 있는 entry
routing objects = internal node에 있는 entry
Structure of the M-tree
root node는 제일 큰원을 뜻함

internal nodel Op, Oi, Oj는 각 원의 중점을 의미함
Om은 Op, Oi에 속해있지만 트리에서는 Op에만 속해있음
즉, 원안에 속해있는 모든 entry를 포함하지 않는 것을 알수있음
object이 속한 parent node는 단 1개로 표현해야함
실제 object은 leaf노드(ground object)에 있음
위의 구조 아는 것 중요함!
M-tree: Internal Node
4가지의 element로 구성되어있음
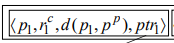
- Pivot: p
- Covering radius of the sub-tree: rc(원의 반지름)
- Distance from p to parent pivot pp: d(p,pp) 더 큰원과 작은원의 중심끼리의 거리
- Pointer to sub-tree: ptr

M-tree: Leaf Node

- object (its identifier): o
- distance between o and its parent pivot: d(o,op)
M-tree 구조

O5, O11에서의 원중심까지의 거리가 살짝 달라서 1.3, 1.0으로 표현한것임
M-tree, single-way insertion
(1개 subtree에 대해서만 object를 삽입)

(root노드 중)Op와 Ow중 Ow에 더 가깝고
Ou와 Ow중 역시 Ow에 더 가까움

그러므로 노란색 영역에 Onew가 추가되고
빨간색 원이 노란색 영역까지 커짐
complextigy: O(log(n))
M-tree, multi-way insertion
여러개의 가능성을 타진해보고 원의 중심과 가장 가까운 곳에 삽입하는 것
complextigy: O(n)
insert process
1. recursive하게 탐색한뒤
2. 매 스텝마다 각 pivot p(원의 중심)에 대하여
- 원안에 포함되어 있는 경우: 원의 반지름이 더 작은쪽으로 들어감
(그 중에 가장 짧은 것을 선택= 가까운 원의 중심 선택)
- 원안에 포함되어 있지 않은 경우: 반경이 최소가 되는 원으로 넣어줌
** leaf 노드가 꽉찬 경우 split해야함(split은 생략)
원의 중심 선택하는 방법
- RANDOM – select pivots p1, p2 randomly: 랜덤하게 선택
- m_RAD – select p1, p2 with minimum (r1 c + r2 c): 최소화 하는 두점 선택
- mM_RAD – select p1, p2 with minimum max(r1 c, r2 c): min max dist활용
- M_LB_DIST – let p1 = pp and p2 = oi | maxi {d(oi ,pp)}:
(처음중심은 기존 중심으로 그다음은 그점과 가장 멀게 선택)
split 방법 2가지
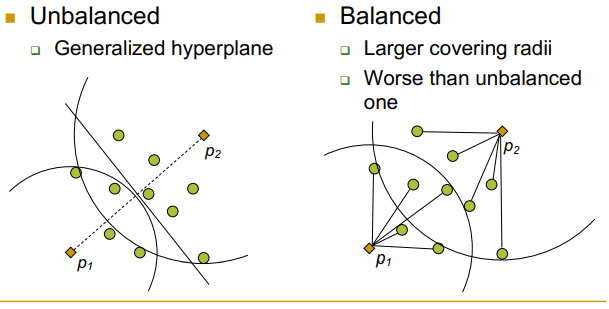
1. Unbalanced: 두 점의 직선거리에 수직이등분하는 선을 기준으로
2. Balance: 한 object씩 나눠 갖는 것
질의 처리(검색)
빨간 점선원 안에 들어오는 모든 object를 찾아라

코드상에서는 각 두점의 거리 R(q,r)을 기준으로 object를 탐색 함
3가지 range search process
1. pivot-pivot constraint
2. range-pivot constraint
3. object-pivot constraint
1. pivot-pivot constraint
아래 조건을 만족하는 경우 pruning이 가능함 (Pp는 parent node의 중심임)


2. range-pivot constraint
겹치는지, 안겹치는지 알기위해서는 아래조건을 만족하는지 확인하면 됨
아래 조건에 해당하면 pruning 하면 됨

3. object-pivot constraint

위조건을 만족하는 경우 pruning하면 됨(무시) = 아래 그림과 같은 상황

else 아래와 같은 방법도 만족하지 않으면 pruning하면 됨


예제) range-pivot constarint를 사용하여 range search 하기(중요)

'IT > 공간정보처리시스템' 카테고리의 다른 글
| Road Network Query Processing (0) | 2022.11.16 |
|---|---|
| Spatial join (0) | 2022.11.09 |
| R-tree를 활용한 다양한 질의 처리 (0) | 2022.10.23 |
| R-tree (0) | 2022.10.22 |
| z-ordering Tree (0) | 2022.10.13 |