728x90
오늘은 간단히 kkma를 import 해서 word cloud를 그려보려고 해요.
5가지 단계로 나눠봤으니 천천히 따라오시면 됩니다.
우선 간단히 kkma를 import 하시고 comment라는 파일을 불러옵니다.
1. 단어추출
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from konlpy.tag import Kkma
kkma = Kkma()
import pandas as pd
# 한글파일이라 cp949로 encoding 해줍니다.
cmt = pd.read_csv('comment.csv',encoding='cp949')
# 2021년 목표글에 있는 단어들을 추출해서 list로 만들어주는 함수
def create_n(table):
# final 이라는 list에 단어들을 추출해서 담을 예정
final=[]
for i in range(table.shape[0]):
list_n=kkma.nouns(table['2021년목표'][i])
final=final+list_n
return final
|
cs |
위의 create_n이라는 함수를 작성해서 2021년 목표글에 어떤 단어들이 있는지 추출합니다.
[output]
|
1
|
goal_list=create_n(cmt)
|
cs |

2. 단어 카운트
이 결과는 단순히 단어들을 쭉 나열한 것이기 때문에, 어떤 단어들이 가장 많이 활용되었는지 보기위해
아래와 같이 단어별 빈도를 확인해 줄 수 있는 함수를 한번 더 돌려볼게요.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 추출된 단어를 count해주는 함수
def getNounCnt(post_list):
noun_cnt = {}
for noun in post_list:
if noun_cnt.get(noun):
noun_cnt[noun] +=1
else:
noun_cnt[noun] = 1
return noun_cnt
goal_dict = getNounCnt(goal_list)
# series 형태로 변환
goal_series = pd.Series(goal_dict)
# 2번이상 언급된 단어들만
goal_cnt=dict(zip(goal_series[goal_series>=2].index.tolist(), goal_series[goal_series>=2].values.tolist()))
|
cs |
goal_cnt 의 결과는 아래와 같아요.
[output]

3. word cloud 그리기
이제 위의 결과를 가지고 워드클라우드를 그려보겠습니다.
저는 사람의 이미지를 가져와서, 그 위에 그려보려고 해요.
|
1
2
3
4
5
6
7
8
9
|
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 웹사이트에서 iconpp.png라는 파일을 다운받아 분석 환경에 미리 upload 해줍니다.
icon=Image.open('iconpp.png')
mask = Image.new("RGB", icon.size, (255,255,255))
mask.paste(icon,icon)
mask = np.array(mask)
|
cs |
그 다음 워드클라우드를 그리기 위한 환경설정을 해주고 그림을 그려보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
!pip3 install wordcloud
from wordcloud import WordCloud
wc = WordCloud(font_path='NanumGothic.ttf', #폰트
background_color='white', #배경색
width=800, height=600, #사이즈설정
max_words=200 #단어갯수
,mask=mask
) #마스크설정
cloud = wc.generate_from_frequencies(goal_cnt) #사전형태의 데이터
plt.figure(figsize=(10,10)) #액자사이즈설정
plt.axis('off') #테두리 선 없애기
plt.imshow(cloud,interpolation="bilinear")
|
cs |
[output]

4. 가장 많이 쓴 단어 10개 보기
Counter라는 함수를 사용해서 위의 그림에서 나온 단어들이 빈도가 어떻게 되는지 볼 수 있어요.
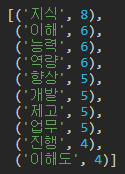
5. 특정단어가 사용된 문장 확인하기
|
1
2
3
4
|
for i in range(cmt.shape[0]):
sentence=concordance(u'지식',cmt['2021년목표'][i], show=True)
if sentence=='':
print(sentence)
|
cs |
[output]

728x90
'IT > 파이썬' 카테고리의 다른 글
| applymap 활용하기 (0) | 2021.01.05 |
|---|---|
| one-hot encoding(원-핫 인코딩) (0) | 2021.01.04 |
| Permutation Feature Importance(변수중요도)를 통한 feature selection (0) | 2020.12.24 |
| Dummy Classifier (0) | 2020.12.23 |
| Lasso regression(라쏘 회귀분석) (0) | 2020.12.22 |