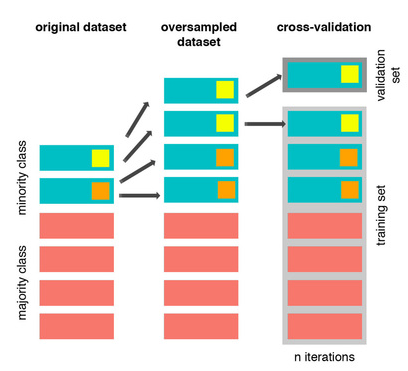
지금 분석 하려고 하는 내용은 복잡하니, 개괄적인 내용만 미리 정리해보겠습니다. 우선 Imbalanced Dataset를 모델링시키기 위해서는 아래와 같은 순서로 진행합니다. StratifiedKFold기법을 적용하여, train과 test dataset으로 쪼개고 Train dataset의 Minority class를 over sampling하고 over sampling 된 traing dataset으로 모델을 Traning 시킨 후 원래 데이터의 test dataset을 통해 test한 후 모델설명력을 평균 내는 것 (cross validation의 원리) 왜 imbalanced dataset에서는 위와 같이 복잡하게 진행할까라고 하시는 분들은 아래 설명을 보시면 조금 이해가 될거 같습니다. www...