Syntactic parser: 문법을 이용하여 문장의 구조를 찾아내는 process
(parse tree참고)
Tree관련 용어정리
Node : Non-terminal node
eg. 명사구, 동사구, 형용사구, 부사구, 전치사구
Link
Root: S = sentence
Leaves
Grammar: a set of rewite rules(CFG참고)
Context Free Grammar (CFG):
1. N: a set of non-terminal symbols (S, NP, VP 등)
2. ∑: a set of terminal symbols (N, V 등)
3. R: 아래와 같은 parsing 규칙룰을 표현
단, 왼쪽에 있는 항들은 모두 한개의 non-terminal이어야 함.
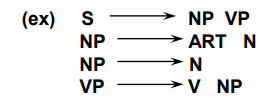
4. S: start symbol을 의미
Example of CFG(공항정보시스템)

CFG외의 다른 Grammar type
Generation Power(chomsky Hierarchy)
- Type 3 Grammar (Regular Grammar) -> 제약조건이 가장 많음
- a: 하나의 nonterminal
- b : NT+Ti 또는 Ti +NT (Ti 는 terminal들, NT 는 nonterminal)
- Type 2 Grammar (Context Free Grammar)
- a : 하나의 nonterminal
- b : any combination of terminals and nonterminals
- Type 1 Grammar (Context Sensitive Grammar) --> Non-decidable
- a : 하나의 nonterminal과 여러 개의 terminal의 any combination
- b : any combination
- Type 0 Grammar --> Non-computable
- a : any combination
- b : any combination
즉, 3, 4같은 경우에는 더 유용하나 컴퓨터 기법으로는 계산하기에 한계가 있다.
그래서, sub-categorization 정보를 활용하여 parsing을 하면 됨
** sub-categorization정보: 1형식 2형식 동사에 대한 내용과 같음
Parsing 종류
1. Top-down parsing
2. Bottom-up parsing
두 종류 모두, 많은 옵션을 고려한 뒤에 parsing 구조를 만들 수 있다는 점이 있다.
Dynamic Programming Parsing
CFG의 단점을 해결하고자, Dynamic Programming Parsing 기법은
intermidiate results를 저장(cache)해놓는 방법을 사용한다.
ex) Tabular parsing
DPP의 복잡도는 O(n3)이며 여기서, n은 단어의 갯수(문장의 길이) 이다.
Dynamic Programming Parsing의 역사
1. CKY(1965) : bottom-up
2. Earley parser(1970) : top-down
3. chart parsers(위의 것보다 쫌 더 대중적임)
CKY Parser (Bottom-up 방식)
- 문법구조를 CNF(Chomsky normal form)을 사용해서 구조화 시킨다.
CNF구조는 CFG와 유사하지만 오른쪽 항의 규칙이 추가됨
(오른쪽 항에는 무조건 1개의 terminal symbol나, 2개의 non-terminal symbol이 들어가야함)
- Bottom-up parser이며, triangular table(Tabular parsing)을 사용한다.
example of CKY parser1

CKY의 복잡도
- 한개의 parse tree를 찾을 경우
총 n(n+1)/2 = O(n2)개의 cell이 있고 각 셀마다 n번씩 계산해 줌으로,
복잡도는 O(n3)임
(강의자료 참고)
- 모든 가능한 parse tree를 찾을 경우,
너무 복잡해짐...(exponential의 complexity를 가질 수 있음)
Tomita's Parser (Generalized LR Parser)
- modified LR Parser
- 장점: 매우 빠르다
- 단점: LR table을 저장하기 위한 space가 필요하다.

Features and Augmented Grammar
1. This program works well.
2. This programs work well. (x)
3. These program works well. (x)
4. These programs works well. (x)
1번을 제외하고 모두 문법적으로 틀린 문장이고
이런 것을 parsing할때 효과적으로 사용하기 위해서는
features and augmented grammar를 사용함
--> feature structure로 표현

모든 자료는 서정연 교수님의 자연언어처리과목 수업 내용입니다.
'IT > 자연어분석' 카테고리의 다른 글
| [자연어]Statistical Parsing (0) | 2022.04.20 |
|---|---|
| [자연어]Part of Speech Tagging, Sequence Labeling, HMM (0) | 2022.04.08 |
| [자연어]N-gram (0) | 2022.03.28 |
| [자연어]형태소 분석 방법 (0) | 2022.03.13 |
| 텍스트 마이닝 용어정리 (0) | 2022.03.04 |