Part of speech
Part of speech tagging(PoS): 각 문장에 품사를 붙여 주는 것
한국어 PoS tag: 46개
영어 PoS tag:
- Noun
- Verb
- Adjective(형용사)
- Adverb(부사)
- Preposition
- Determiner: 관사, WH-determiner(which, that)
- Coordinating Conjunction: and, but, or
- Particle: 연결부사(take off에서 off와 같은 것들)
Closed class categories: Pronouns, prepositions, modals, determiners, particles, conjunctions
Open class categories: 명사, 동사, 형용사, 부사
2가지 POS tagging approaches
1. rule-based: 규칙을 만드는 것은 어려우나
2. learning-based : tagging을 하는 것은 쉬움
** classification learning도 있는데, iid가정은 language모델에 적합하지 않음
따라서 language 모델 경우, sequence labeling을 고려해야함
Sequence Labeling
sequence labeling: 문장에는 어순(sequence)가 있음
아래와 같이 sequence labeling을 활용하는 다양한 방법이 있음
1. named entity recognition: 문장에서 객체(People, Places, Organizations)를 인식하는 것
--> PLO tagging: People, Place, Organization tagging
--> named entity에서는 여러단어가 합쳐져서 named entity가 될 수 있음
eg) Dell Computer Coporation과 같이 하나의 entity
2. Semantic Role labeling (SRL)
절(주어+동사)내에서 명사의 의미적 역할을 파악하는 것
= a.k.a "case role analysis" or "thematic analysis"
--> John(운전자) drove from Austin(출발지) to Dallas.(목적지)
3. Bioinformatics
genome 분석에서 genetic sequence labeling으로도 사용됨
eg) AGCTACGTTCGATACG......
Problems with Sequence Labeling as Classification
sequence로의 classification을 해줘야함
(각자 단어의 품사 분류보다 더 어려움)
--> 해결책: HMM, CRF
Sequence Model에서 주료 사용하는 모델들
1. HMM: Hidden Markov Model (HMM)- 계산 단순
2. Conditional Random Field (CRF)- 성능 높음
--> HMM보다 CRF가 계산이 더 복잡하나 성능이 좋음
HMM
Markov chain: A finite state(유한상태) machine with probabilistic state transitions.
= Bigram
= First-order Markov Model
= N-1 order Markov Model
유한상태 machine: 입력이 들어왔을 때 다른 유한개의 상태로 전이할 수 있는 machine
Markov assumption: 다음 상태는 바로 이전상태에만 영향을 받고 그 이전상태와는 independent하다고 가정하는 것
Marcov chain의 3요소
1. a set of states
2. Transition probabilities
3. start, end states
Markov chain의 수식적 정리

HMM: Markov model에서는 상태정보를 직접적으로 알 수 있었다면
HMM은 상태정보를 알수있는 간접정보만 있음
--> 문장에 나온 단어들을 통해 품사정보를 알아 내는 것
HMM의 구성요소
Q: N개의 상태 set
A: transition probability = aij
O: observation(단어열)
B=bi(Ot): t번째 단어가 i번째 state가 될 확률(관측확률)
q0, qF: start와 end 상태
HMM의 수식적 정리

j번째 날씨(품사)에서 t번째 아이스크림갯수(단어)가 될 확률
= 즉, Qj가 나타났을때, Ot가 나타날 확률 P(Ot|Qj) <-output independence assumption이 적용됨
B: observation likelihoods = emission probabilities = 관측확률
(아래 박스에 표시된 확률들)
HMM의 2가지 가정
1. Markov assumption
2. Output-independence assumption

단어가 O1(observation)부터 Ot-1까지 있고, Qt품사일 때 단어 Ot가 나타날 확률(왼쪽)
이전상태에 focusing을 주기보단
현재에서 어떤 Qt품사(날씨)일때 단어(아이스크림) Ot가 나타날 확률로 정하자(오른쪽)
HMM diagram

Different types of HMM structure
1. left-to-right
2. fully-connected
The Three Basic Problems for HMM
(아래와 같은 문제에서 HMM을 사용함)
1. Evaluation
--> 모델하에서 input sequence가 나타날 확률 P(O|λ)
--> 하지만 너무 많은 조합이 있음
--> 품사(46개)가있을 때 4개의 단어의 input sequence가 나타날 확률은 46**4임
--> CKY Parsing(dynamic programming algorithm)과 같은 방법으로 풀어나감
--> CKY Parsing(중간단계 값을 저장하는 테이블 사용)과 같이 forward algorithm을 활용
2. Decoding
--> 단어가 나타났을 때 가장 적합한 품사를 매핑해주는 것
--> 숫자가 나타났을 때, 가장 적합한 날씨를 매핑해주는 것
3. Learning
--> How do we adjust the model parameters λ= (A,B) to maximize P(O| λ)?
--> 즉, 모델의 파라미터를 학습할 때 사용
--> λ= (A,B)에서 A는 transition probability, B는 observation probability
Forward algorithm
아래 수식 이해하기

** initialization에서 a0j는 transition probability임
Forward algorithm의 한 줄 수식 정리는 아래와 같음

--> t번째 observation이 들어왔을때, Qj의 상태가 되는 확률을 ∂t(j)라 함
HMM-Decoding
이것도 역시 evaluation의 경우와같이 많은 조합을 계산해야함
--> 품사(46개)N개가 있을 때 4개(T)의 단어의 input sequence가 나타날 확률은 46**4임
--> 해결책: Viterbi algorithm
Viterbi algorithm 한줄 정리

**Viterbi backtrace참고하기
아래 수식 이해하기

initialization에서 bt1(j)=0은 각각 수행하는 단계마다 제일 큰 값이라고 생각하는 것의
index를 저장하는 것이라고 생각하면 됨(backpointer라고함)
HMM정리
HMM은 probabilistic generative model for sequences 이다.
HMM문제를 풀기위해서는
- hidden state가 존재해야하고
- probabilistic transitions between states가 존재해야하고
- probabilistic generation of tokens from states가 존재해야함
( P(3|H)와 같은 값이 존재해야함 )
HMM - Learning
a. Supervised HMM Training
a-1. transition probabilities

위의 수식을 예를들어 설명하면
Qt번째 단어가 Si(동사)가 될 모든 경우의 수 = 분모
Qt번째 단어가 Si(동사), Qt+1번째 단어가 Sj(명사)가 될 모든 경우의 수 = 분자
분자를 보면 bigram probability와 같다는 것을 알 수 있다.
a-2. observation probabilities
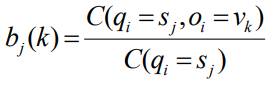
= P(book | noun) 와 같은 확률
--> book=Vk, Sj = noun
--> 즉, Qt번째 단어가 명사인데 그게 book이라는 단어일 확률
HMM - Learning 방법
1. HMM의 supervised training을 통해 labeled data를 학습한다.
2. Viterbi 알고리즘을 통해 unlabeled test sequence를 가장 확률이 높은(max) 품사로 tagging한다.
--> development set(validation dataset)을 통해 parameter 튜닝
--> 품사태깅은 accuracy값을 통해 평가함
(현재 알려진 HMM포함한 POS tagger의 성능은 96~97%임)
HMM - Learning
b. Unsupervised HMM Training
supervised HMM training이 가장 확률이 높은 품사로 tagging해주는 모델의
파라미터를 찾는 것이라면,
unsupervised HMM training은 observation O가 나타났을 때,
모델 λ의 어떤 파라미터가 이 모델을 통해 O의 문장(observation)이 생성될 확률을
제일 높게해주는 것인가를 푸는 문제임
(즉, observation probability를 최대로 하는 λ를 찾는 것 = P(O|λ)를 찾는 것)
--> 이 문제를 풀기위해서 Baum-Welch algorithm(a.k.a forward-backward)
or Expectation Maximization(EM)알고리즘을 사용함
EM 알고리즘
1. 문장에 random하게 품사를 tagging한다.
2. 위의 randomly mapping된 품사를 통해 확률값을 계산한다.
3. 그 randomly mapping하는 모델을 가지고 다시 tagging(expectation)
4. 그 모델의 parameter를 다시 계산(maximization)
(re-estimate values for all of the parameters λ)
--> 3 & 4번 반복
EM 알고리즘 특성3가지
1. 각 iteration은 P(O|λ)의 확률값을 증가시키는 것을 보장한다.
(성능증가 보장)
2. Anytime algorithm: Can stop at any time prior to convergence to get approximate solution.
(수렴되기전 아무 iteration에 멈춰도 대략 좋은 성능을 내는 알고리즘을 get할 수 있음)
3. Local maximum에 빠질 수 있음
** N개의 상태값이 있다는 것은 미리 알고있어야 함.
HMM - Learning
c. semi-supervised HMM Training
EM 알고리즘에서 labeled data와 unlabeled data를 둘다 사용하는 것
초기 단계에서 labeled data로 모델을 만들고
다음단계에서는 unlabeled data를 사용해서 EM알고리즘을 적용

Semi-supervised learning을 사용하는 이유:
어느정도의 labeled data는 확보할 수 있지만 모든 데이터에 labeling을 할 수 없기 때문에
Negative effect of semi-supervised learning:
Semantic labeling값도 learning 함
본 내용은 서정연 교수님의 자연언어처리 내용 정리된 것입니다.
'IT > 자연어분석' 카테고리의 다른 글
| Word Vector and Word embedding (0) | 2022.05.06 |
|---|---|
| [자연어]Statistical Parsing (0) | 2022.04.20 |
| [자연어]N-gram (0) | 2022.03.28 |
| [자연어] Grammar & Parsing (0) | 2022.03.16 |
| [자연어]형태소 분석 방법 (0) | 2022.03.13 |