Pre-trained Language Representations 2가지
1. Feature-based approach
2. Fine-tuning approach
1. Feature-based approach
특정 분석을 수행하기위해 architecture에서
input을 기존의 word vector(파란색)뿐만 아니라, ELMo통해 추가로 얻은 feature를 더해줘서 넣어주는 것

2. Fine-tuning approach
대규모로 language modeling을 진행후, 약간의 튜닝을 통해
원하는 분석작업에 적용하는 것
→ BERT, GPT3가 있음
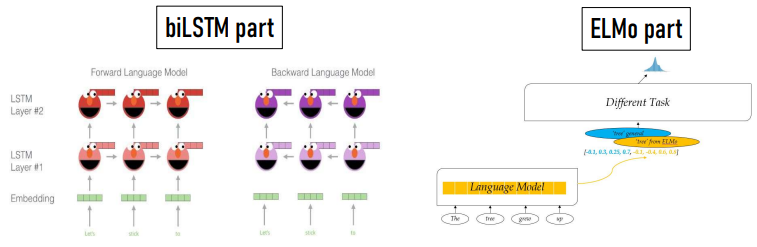
ELMo
ELMo는 word2vec에서 불가능했던 동음이의어를 처리하기 위해
문장전체(양방향)를 가져와서 단어를 처리하자는 것임
eg) I need a fan...??? (left-to-right)
eg) fan to cool the heat (right-to-left)
→ 여기서 fan은 연예인의 fan이 아닌 선풍기의 fan임
** word2vec과 달리, ELMo/GPT/BERT는 context를 보기 때문에
input 자체가 그냥 문장 통채로라고 생각하면 됨
ELMo를 구성하는 두가지 components:
pretraining part: bi-LSTM
ELMo part
Attention Mechanism
- BERT, GPT등은 LSTM대신에 아주 층층이 쌓아져있는 transformer를 사용함
(참고로, transformer는 positional encoding이 되어있어 단어의 위치정보도 제공함)
- LSTM에서 input/forget gate등의 역할을
transformer에서는 attention이라고 함.
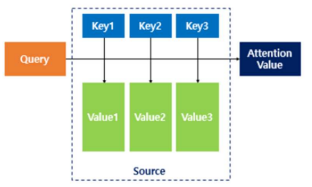
1. context vector를 구하기 위해 각각 score를 계산함

2. 각각의 스코어를 alignment weights로 변환함

3. context vector를 생성하여 weighted average를 다음 hiddent state에 반영해줌

3가지의 attention종류

- Encoder-Decoder attention:
Query: 디코더 벡터
Kye, value: 인코더 벡터
query에 대해서 모든 key와 유사도를 구하고,
유사도를 가중치로 하여 key와 mapping된 각 value에 반영
→ 최종적으로, 유사도가 반영된 값을 모두 가중합하여 리턴하는 것임
- self attention이란: key=Query=Value인 것

eg) “그 동물은 길을 건너지 않았다. 왜나하면 그것은 너무 피곤하였기 때문이다.”
여기서 "그것"이 가리키는 것을 찾기위해 동일문장으로 활용하여 찾아내는 것
Attention mechanism 적용 장점
매번 decoding을 수행할 때마다 생성하고자 하는 단어가
source sentence의 어느 부분과 관련이 높은지를 계산해서 생성과정을수행하므로 성능이 좋음
구글 transformer
BERT는 아래그림과같은 encoder(양방향)를 12개 쌓아서 만든 모형이고
GPT는 decoder(left to right)를 사용하여 만든 모형임
따라서 GPT는 Generation에 매우 강함(기사 만들기)

BERT preprocess 코딩관련 내용
- is_split_into_words=True
: bert에서 입력되는 input은 다 토큰으로 이미 split되어있는 구조임
- label_all_tokens=True
: 모든 토큰의 label이 맞았을 때 정답으로 처리하는 경우 True값을 넣어줌
'IT > 자연어분석' 카테고리의 다른 글
| BERT2 (0) | 2022.05.26 |
|---|---|
| LSTM and Sequential Labeling (0) | 2022.05.25 |
| Word Vector and Word embedding (0) | 2022.05.06 |
| [자연어]Statistical Parsing (0) | 2022.04.20 |
| [자연어]Part of Speech Tagging, Sequence Labeling, HMM (0) | 2022.04.08 |