1. bellman equation
Bellman Equation - V에 대하여

>> 그 state에서 어떤 action을 취했을 때의 reward와 그 다음 state에서의 가치의 합이다.
[Stochastic environments] stochastic한 환경에서 다음단계로 이동할 때

위의식을 일반화하면


여기에서 우변을 bellman backup이라고 함
[Stochastic environments] stochastic한 policy로 다음단계로 이동할 때

**pi 는 policy라는 뜻임
더 간단히 아래와 같이 표현할 수 있음

Bellman Equation - Q에 대하여

[Stochastic environments] stochastic한 환경에서 다음단계로 이동할 때

[Stochastic environments] stochastic한 policy로 다음단계로 이동할 때

여기서 stochastic policy에 대한 수식이 다른 이유는
다음단계에서 어떤 action을 취하는지에 대해서면 확률적으로 정해지기 때문임
(왜냐하면 이미 a단계에서의 action은 정해져서 그 다음단계로 이동하기 때문에)
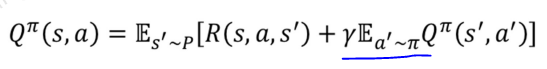
아래와 같이 더 간단히 표현할 수 있음
Bellman Optimality Equation - v에 대하여
optimal value 표기방법

모든 액션중에 bellman equation을 max로 만드는 policy에서의 가치
수식으로 표현하면 아래와 같음

Bellman Optimality Equation - Q에 대하여

>> 다음 단계에대해서 최대값을 가져야지 현재값에서 최대값을 가질 수 있음
위의 내용을 최종적으로 정리하면
(아래 수식은 직접 써보기…)

2. Relationship between Value and Q Function
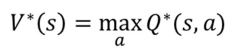
아래 값에 위의식을 적용 해보면
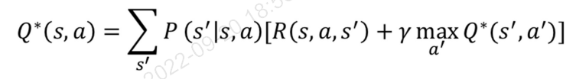
아래와 같이 표현할 수 있음

또한 이렇게도 표현할 수 있음

3. Dynamic Programming - Value Iteration
Note: dynamic programming is a model-based method.
Value iteration알고리즘의 목적
- optimal value function을 구한다.
- 위의 계산된 값을 활용하여 optimal policy를 얻는다.
아래와 같은 환경이 있다고 생각해보자.

0-left/right, 1-up/down 일 때, 아래와 같은 테이블을 만들 수 있음

이 모든 값의 Value를 계산하기위해 아래와 같은 iteration방법을 사용함
(Dynamic programming)

V(A) = V(B) = V(C) = 0로 초기화함

이 식을 기반으로 위의 테이블을 업데이트함
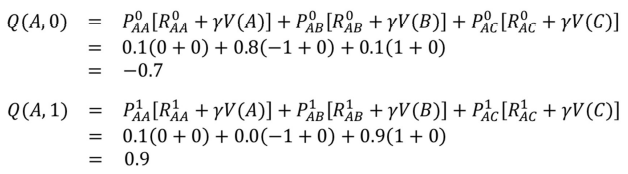
위의 두 값 중 MAXIMUM 값을 v(A)로 표기함
어느정도 수렴이 되면 마지막으로 Q값을 계산하기 위해 한번 더 수행함

이 값을 가지고 Q테이블에서 최적의 policy를 정함
[코드 구현]
is_slippery=False : deterministic 환경임
is_slippery=True : stochastic 환경임
** is_slippery=False일 때는 gamma 값을 1보다 작게해야함
** 만약 gamma를 1로 하면 가치가 다 같으므로 무한 뺑뺑이로 돌아다닐 수 있음

threshold = 1e-20 : 제시한 값임
def value_iteration(env):
num_iterations=2000
threshold =1e-20
gamma =0.99
value_table =np.zeros(env.observation_space.n)
# size 16의(observation_space를 가져옴) numpy array를 0으로 채움
cnt=0
for i in range(num_iteration):
updated_value_table= np.copy(value_table)
for s in range(env.observation_space.n):
Q_values = [sum([prob*(r + gamma *updated_value_table[s_])
for prob, s_, r, _in env.p[s][a]]) # 확률, 다음상태, reward값
for a in ragne(env.action_space.n])
value_table[s] - max(Q_values)
if np.sum
....
argmax는 max값을 만들어주는 Q의 인덱스라고 생각하면 됨
maximum의 interation을 넣어도, threshold에 봉착하면 멈춤
stochastic environment에서 학습결과 경로는 아래와 같이 표현 됨


[gamma에 대하여]
gamma를 0.99로 준다는 의미는
목적지에서 멀어질수록 가치가 떨어짐을 의미함
| 0.99^4 | |||
| 0.99^3 | |||
| 0.99^2 | |||
| 0.99 | 1 | G |
만약 gamma를 1로 하면 가치가 다 같으므로 무한 뺑뺑이로 돌아다닐 수 있음
4. Dynamic Programming - Policy Iteration
policy iteration vs. value iteration

1. Initialize a random policy.
초기에는 random policy를 정함 ( deterministic policy)
(매순간 random 하게 이동하는 것이 아니라, 초기에 randomly policy를 세팅함)

2. Compute the optimal value function using the given policy iteratively.
3. Extract a new policy using the value function obtained from step 2.

4. If the extracted policy is the same as the policy used in step 2,
then stop, else send the extracted new policy to step 2 and repeat steps 2 through 4.
( policy에 수렴하게 되면 stop)

초기에는 모두 0으로 세팅함

파란색 괄호는 value table을 업데이트 해주는 것
파란색 괄호는 55페이지와의 차이를 알 수 있는 부분임!!
value iteration에서는 action을 action_space에서 임의로 정하는데,
policy iteration에서는 action을 미리 셋팅해놓고 시작함
왜 policy iteration, value iteration 개별로 update하는 로직이 있는가?
→ 상황에 따라 유용한 iteration이 다르다.
→ action이 10000가지 일 때 모든 action에 대해서 value값을 업데이트 하는 것보다
policy에 대해 update해서 value값을 정하는 것이 편함
'IT > 강화학습' 카테고리의 다른 글
| Temporal Difference Learning (0) | 2022.10.25 |
|---|---|
| Monte Carlo methods - Importance Sampling (0) | 2022.10.12 |
| Monte Carlo methods (0) | 2022.10.11 |
| Frozen Lake 구동해보기 (0) | 2022.09.17 |
| 강화학습 소개 (2) | 2022.09.13 |