2.1 음성 신호 저장 방법 및 시스템 입력
음성 신호의 저장 방법 (sampling rate: 16K, Sample 당 byte수 )
1. sampling rate: 단위 시간당(초당) sampling의 횟수
음질이 안좋으면 sampling rate이 낮음
- 유선전화는 1초당 8k임
- 음성인식의 sampling rate: 16k (초당 16000번 sampling 하는 것임)
2. Sample 당 byte수
⁻ Sample당 2byte 사용 2^16 = 65,536
(1초의 음성을 녹음하면 16000*2byte의 저장용량 필요)
** 참고

왜 window별로 feature를 추출하는가?
추출해야하는 항목들
- frequency, 증폭, 위성(sin곡선이 x축기준으로 얼마나 움직이는가)
- stationary한 소리: 엔진소리
- non-stationary한 소리: 사람의 말(음성)
non-stationary한 음성을 분석(또는 예측)하기 위해 짧은 단위로 쪼개는데,
이것을 20ms로 slicing하는 것이 일반적인 방법임
- 20ms(1/50초 단위)로 slicing 하면 어느정도 stationary함(=quasi-stationary)
- 하나의 window에는 320개의 sample이 들어감 (16000/320 = 50)
Fast Fourier Transform (FFT)
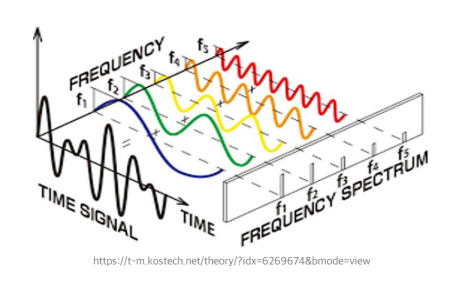
Time signal의 input이 들어왔을 때, f1+f2+f3+f4+f5(sin함수의 합)를 구하는 것
(역방향으로 복원하는 것은 불가능함)
spectrogram이란?
특정 time T(y축)에 대해 frequency별(x축) 에너지(z=amplitude)의 3차원 그래프를 나타낼 수 있는데
그 에너지를 색으로 표현한 것임
(spectrum은 frequency별 에너지를 보는 것임)

Mel-filterbank & Log
x(n) = v(n)*e(n) 을 음성이라고 가정
⁻ v(n) = 구강구조
⁻ e(n) = 성대에서 울리는 소리
v(n)은 음성에 대한 정보에 관심이 있음 ⁻ 무슨 말을 했는지에 대한 정보
e(n)은 화자에 대한 정보에 관심이 있음 ⁻ 어떤 사람이 말을 했는지에 대한 정보
1. x(n) = v(n)*e(n) 이 마이크를 통해 입력됨
2. FFT를 통해 frequency domain으로 변환 ( convolution이 곱셈으로 변환)
3. X(n)에서 화자 정보인 e(n)을 제거하기 위해 log를 씌워 덧셈으로 변환
→ Log(X(n)) = Log(V(n)) + Log(E(n))
Discrete Cosine Transform(DCT)
- 적은 차원의 데이터로 envelop을 구할 때 사용됨
- Discrete Cosine Transform(DCT) 과정을 통해 음성 인식에 있어 필요한 정보만을 담은 13차 vector를 생성
→ 13개의 vector(feature)로 표현하는게 가장 좋다는 것을 실험적으로 알아냄

MFCC feature 추출 과정

13개의 직교하는 eigen vector를 추출하는 것임(독립)
→ 결론: window size내에서의 음성인식을 구분하기 위한 최대한의 정보만 뽑아내는 작업임
2.2 음성 출력 단위 결정 (Tokenization)
한국어는 형태소단위로 끊음
(2200개의 한국어 음절)
영어는 단어단위(띄어쓰기)로 끊음
Tokenization Algorithm
1. byte-pair encoding (Sennrich et al., 2016) - frequency가 높은 방향으로
2. unigram language modeling (Kudo, 2018)
3. WordPiece (Schuster and Nakajima, 2012) - 복잡도를 줄이는 방향으로
BPE (byte-pair encoding)
1. 모든 단어들을 글자(character) 단위로 분리
2. 가장 빈도수가 높은 unigram의 쌍을 하나의 unigram으로 통합
예) 가장 빈도수가 높은 unigram이‘A’, ‘B’ 일 경우, ‘AB’를 vocabulary에 추가
3. k번 동안 2를 반복함
4. 결과적으로 vocabulary에 k개의 새로운 unigram이 추가됨
'IT > 음성인식' 카테고리의 다른 글
| Attention의 Q, K, V와 Transformer (0) | 2023.04.12 |
|---|---|
| Vanilla RNN & Seq2seq & attention (0) | 2023.04.05 |
| RNN (0) | 2023.03.29 |
| Feed Forward Neural Net (0) | 2023.03.22 |
| 음성인식 개론 - 특징 (0) | 2023.03.08 |