Query: decoder time t=4일 때 encoder에서의 context vector를 구해주세요. (query는 decoder에서 나오는 것임)
key: encoder vector에서 내적 대상이 되는 set이 key 임(encoder에 있음)
value: weight하고 곱해지는 vector의 set이 value임( value도 encoder 에서 나오는 것임)
Recurrent model의 단점
◼ 정보 손실
Recurrent connection은 정보 손실을 유발
◼ 학습
Recurrent connection은 vanishing gradients와 같은 문제로 학습이 어려움
◼ 병렬처리
Recurrent connection은 sequential하게 처리되야 하므로 병렬 처리가 어려워 학습에 시간이 오래 걸림
→ decoding에서는 이슈가 없으나, encoding에서는 병렬처리가 안되면 학습이 잘 안됨
→ 해결책: self-attention
Transformer개론
똑같은 dimension을 가지는 vector를 다시 뽑는 것임
음성에서는 음성인식률을 제일 높게하는 (=똑같은 dimension을 가지는) vector를 다시 뽑는 것
마이크에서 들어오는 음성중에서 음성인식률이 제일 높은 vector(=똑같은 dimension)를 뽑는 것
→ feature parameter extraction의 과정이라고 생각하면 됨
논문에서는 512차원으로 사용하고 있음병렬로 처리함 (전체 문장을 chunk로 잘라서 넣음 - 1024의 길이정도: 최대 input 길이)
→ 512*1024의 output이 나오는 것임 ( feature parameter extraction)
음성인식에서의 output은 word sequence임

Attention vs Self-Attention
self-attention은 QKV가 다 encoder에서 나오는 것임
self-attention은 feature paratermeter extration 된 vector가 output으로 나옴
장점) 들어온 전체정보(전체 입력 sequenc)를 다 보고 나에 맞는 feature extration vector를 구할 수 있음
page13:
time =3 일때, x1*x3, x2*x3, x3*x3을 내적해서 y3를 구하는 것임
bottlenect구조 (설명다시듣기)
transformer의 단점:
decoder에서 첫번째 잘못 예측하면 그 잘못예측한 값을 또 self attention하므로 계속 에러가 누적됨
** 참고
residual connection: 건너뛰는 것(16page)
Scaled Dot-Product Attention사용하는 이유: vector similarity를 계산하기 위해 (중요하지 않음)(18page)
positional encoding
positional encoding을 이용해서 상대위치를 알 수 있음 (page20)
- Input vector의 index를 sequence의 길이로 나누어 [0,1] 범위의 값을 사용
단점) (다시듣기..ㅠㅠ) 거의 끝나기 13분전
장점) 매 dimension이 더해지는 값 자체가 0~1사이임 (normalized 된 값)
추가 업데이트 내용) 나중에는 one-hot encoding을 사용함
단점) 상대위치를 보기가 어려움
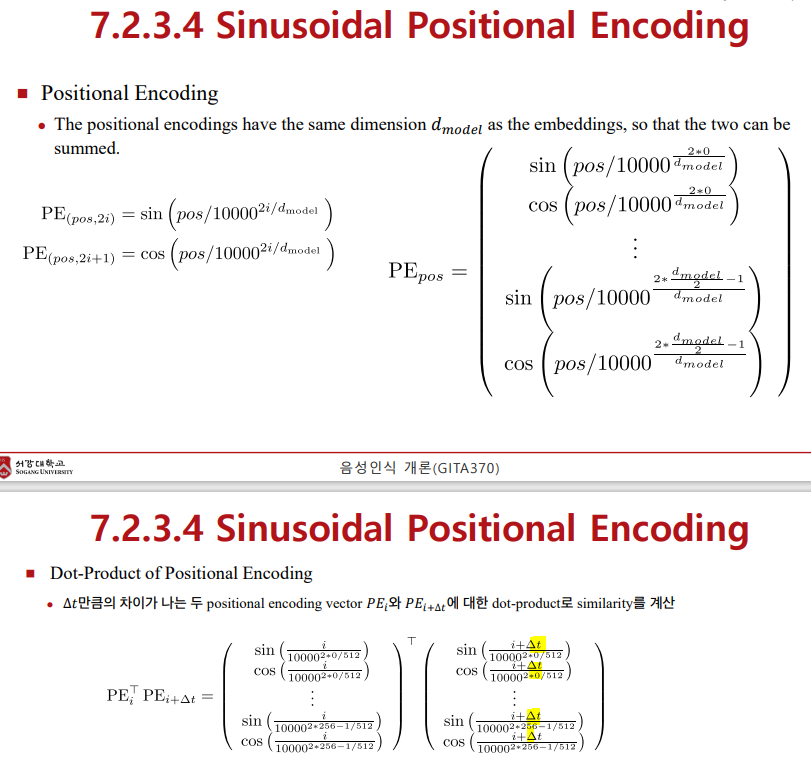
Sinusoidal Positional Encoding
원래 식은 위와 같은데, delta(t)를 사용해서 상대적인 위치만 고려하여 내적하는 것이 아래 내용임
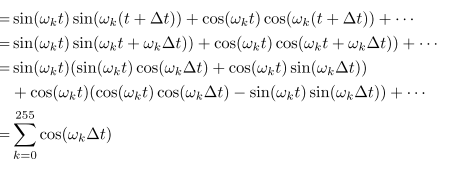
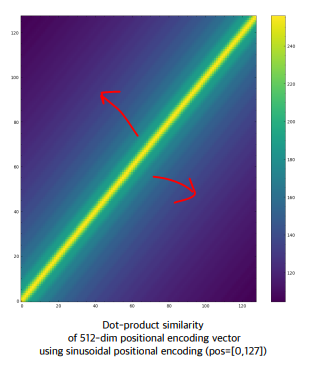
즉, t가 사라지고 delta(t)만 남게되는 것을 알 수 있음
즉, 아래의 대각선만 남고 나머지는 다 중요하지 않게됨??!?!(다시 듣기..)
'IT > 음성인식' 카테고리의 다른 글
| 음향모델 (0) | 2023.05.03 |
|---|---|
| Multi-head attention (0) | 2023.05.03 |
| Vanilla RNN & Seq2seq & attention (0) | 2023.04.05 |
| RNN (0) | 2023.03.29 |
| Feed Forward Neural Net (0) | 2023.03.22 |