8.2.1 인식
8.2.2 Segmentation
8.2.3 학습
음향 모델용 classifier가 가져야 할 특성
⚫ 모델의 구분 단위를 정할 수 있어야 함 (예: 음소)
⚫ 모델이 주어졌을 때 인식 결과 생성이 가능해야 함
⚫ 학습 자료가 주어졌을 때 모델 학습이 가능해야 함
⚫ 대용량 음성코퍼스로 부터 모델 구분 단위별 학습 자료를 자동 생성할 수 있어야 함
⚫ 모델 결합을 통한 문장 인식 확장성
→ 단어에 대한 모델이 문장에 대한 모델로 확장 되는 것
4가지 HMM의 구성요소
1. N개의 상태 (State)
eg) 여우silence 에서는 3개의 state
2. 상태간 천이 확률 (Transition probability)
3. 출력 확률분포 (Output probability distribution)
→ 음성인식은 continuous하므로 pdf(Pr. density function) 형태로 나타남
4. 초기 상태 (Initial state distribution)
** 특정 time T에서 어떤 바구니를 선택했는지 hidden되어있음
** state이동경로나, 어떤 바구니를 선택했는지는 모르지만
** only observation sequence만 알고있음
HMM의 단점
non-deterministic하므로 다양한 경로의 확률이 발생함
→ 속도가 늦다.
HMM의 장점
parameter수가 적음
→ 단, 성능이 좋지 못함 (그러므로 초기에 사용함)
Ergodic 모델 vs. Left-to-right model


HMM 의 확장적 구조

여우단어모델, 문장모델에서 초기상태는 가장 처음에만
1.0이고 나머지는 0.0으로 setting하면 됨
HMM을 이용한 음성 특징 벡터의 생성 예
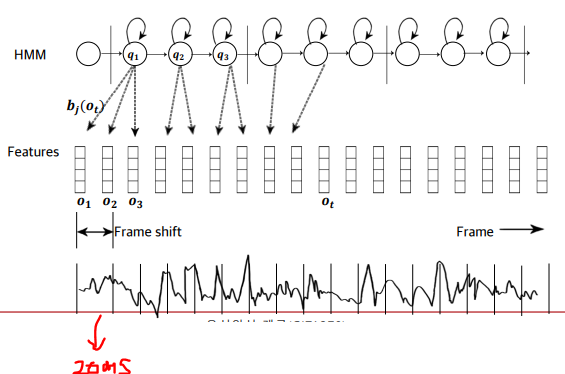
20ms가 17개이므로 총 0.34초의 음성이 입력됨
1. 인식
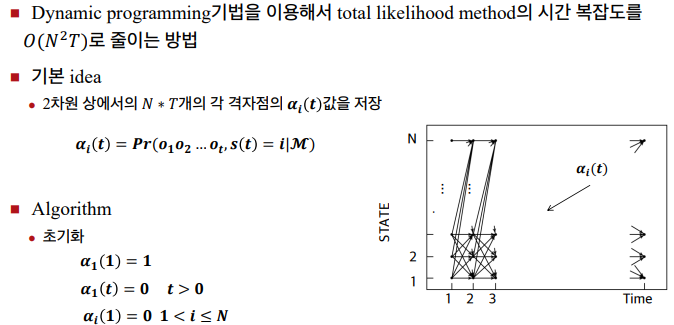
HMM의 세가지 기본 문제

→ 해결책) Dynamic programming기법 (Forward algorithm)
2. Segmentation
아래와 같이 파형(나는 과자)이 들어왔을 때,
어디서부터가 "나"이고 어디서부터가 "는"인지 sementation해주는 것임

Deep Neural Network (DNN)을 이용한 음향모델
Corpus에서 실제로 나타는 tri-phone은 약 1만개임
- ㄱ-ㄱ+ㄱ 등 은 불가능 함
- 이를 seen tri-phone 이라
Tree-based state clustering
- 주어진 학습 자료에 대하여 3 state left-right mono-phone model을 구성함
- Mono-phone model을 training을 거쳐 각 states 마다
single Gaussian output probability density functions을 구함

'IT > 음성인식' 카테고리의 다른 글
| WFST Decoder (0) | 2023.06.07 |
|---|---|
| 언어 모델 (0) | 2023.05.17 |
| Multi-head attention (0) | 2023.05.03 |
| Attention의 Q, K, V와 Transformer (0) | 2023.04.12 |
| Vanilla RNN & Seq2seq & attention (0) | 2023.04.05 |