사후확률이란:
P(ωi|x) x가 주어졌을때 그것이 부류 ωi에서 발생했을 확률
아래그림처럼 분류가 안되는 이유

잘 못된 feature를 뽑았을 경우 분류가 잘 안될 수 있음
확률밀도함수의 필요조건
P(x)가 양수여야되고 P(x)의 모든 합은 1이어야 함
확률기초
d-dimension : random 변수에 해당함 (패턴 인식에서 특징 각각이 랜덤 변수에 해당함)
- 주사위에서 3을 뽑을 것인지 4를 뽑을 것인지
n- sample
c- class
parameter 개수는 (d^2 + d ) / 2임

생각 1
상자 A의 하얀 공 확률과 상자 B의 하얀 공 확률을 비교하여 큰 쪽을 취한다.
P(하양|B)=9/15 > P(하양|A)=2/10 이므로 ‘상자 B에서 나왔다’고 말함
조건부 확률 P(Y|X)를 사용한 셈이다. 타당한가?
이 조건부 확률을 우도라고 likelihood 부름
생각 2
상자 A와 상자 B의 선택 가능성을 비교하여 큰 쪽을 취한다.
P(A)=7/10 > P(B)=3/10 이므로 ‘상자 A에서 나왔다’고 말함
사전 확률 P(X)를 사용한 셈이다. 타당한가?
결론:
생각 1과 생각 2의 한계 극단적으로 P(A)=0.999라면 생각 1이 틀린 것이 확실하다. 극단적으로 P(하양|A)=0.999라면 생각 2가 틀린 것이 확실하다.
결론: 우도와 사전 확률을 모두 고려함이 타당
> 즉 P(X|Y)를 사용하겠다는 생각이 타당하다.
> P(X|Y)를 사후 확률이라 함


- Prior: 상자 A, B가 선택될 확률 : P(wi)
** 사전확률에서는 N이 충분히 커야 실제값이 가까워짐
- Likelihood: sample의 분포 (하얀공의 분포)
= P(x|wi)
= 조건부 확률 활용
= 확률분포함수
- Posterior: P(wi|x)
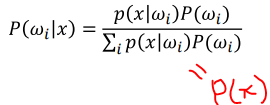
사후 확률을 고려하여 분류하는 것이
사전확률 & likelihood를 모두 고려할 수 있기 때문이 더 좋은 방법임
( 각각이 어떤 것을 뜻하는지 이해하는 것 중요함)
⅀P(x | wi) =1
아래 파란선의 길이와 빨간선의 길이의 합은 1임


노란색 영역은 오류영역임

3번까지는 = sample mean (평균)
6번까지는= sample variance (공분산)
예제)

평균의 dimension= sample dimension = 3
8개의 샘플
최소오류 베이시안 분류기
** 최소오류와 위험은 비례관계에 있음
사후 확률은 직접 구할 수 없음. 왜?
베이스 정리를 이용하여 사후 확률 계산을 사전 확률과 우도로 대치

공통분모이기도 하고, 계산할 수가 없기 때문에 무시함
사전 확률 계산
P(ω1 )=n1 /N, P(ω2 )=n2 /N
정확한 값이 아니라 추정 (N이 커짐에 따라 실제 값에 가까워짐)
우도 계산
훈련 집합에서 ωi에 속하는 샘플들을 가지고 P(x|ωi) 추정
> parametric density function
부류 조건부 확률 이라고도class-conditional probability 함
특수한 경우로
특수경우1. 사전 확률이 0.5인 경우 우도만으로 분류 = equal prior라고 함
특수경우2. P(ω1 )>>P(ω2 )인 경우 사전 확률이 의사 결정 주도
오류확률
오류확률은 파란색 면적의 합

원래 전체 1의면적인 것이 2개가 합쳐지는거라 최대 2의 값을 가지지만,
나누기 2를 해줌으로써 1이하의 값을 갖도록 설정함
t의 지점이 오류를 최소화할수 있는 적정값임 (중요!!)
--> 최소오류 베이지안 분류방법w1이 w2로 분류되는 경우와w2가 w2로 분류되는 상대적 손실이 달라질 수 있음--> risk함수를 계산함 (최소위험 베이지언 분류기)
손실행렬

최소위험 베이지언 분류기
* 오류하고 확률은 반비례
* 확률과 위험도 반비례
* 따라서, 오류와 위험은 비례
위험을 최소화 하는 분류기
1번으로 분류할 때의 risk

2번으로 분류할 때의 risk

위의 식을 같다고 놓고 표현하면

** 0-1 loss function: 최소 위험 분류기와 최소 오류 분류기가 같아지는 것임
사전 확률이 0.5이면 최소위험 분류기 = 최소오류 분류기
(0: 제대로 분류 한 것, 1: 오분류 한것)
분류로직

T ↓ → R1 ↑ (R: region)
T ↓ 가 작아지려면 C21 ↓ or P(w2) ↓ or C12 ↑ or P(w1) ↑ 하는 경우임그러므로 R1 커지는 거라고 할 수 있음
C21 ↓ → P(w2) ↓
(C21 ↓ : 2를 1로 분류하는 위험이 작아짐 그러므로, 1로 분류해도 된다는 뜻이므로
P(w2) 2로 분류하는 확률이 작아진다는 뜻임)
C12 ↑ → P(w2) ↓
C12 ↑ -> P(w1) ↑ & P(w2) ↓ (앞에 1과 비례, 뒤에 2와 반비례) & R1 ↑
C12 ↓ -> P(w1) ↓ & P(w2) ↑ (앞에 1과 비례, 뒤에 2와 반비례) & R1 ↓
C21 ↑ -> P(w2) ↑ & P(w1) ↓ (앞에 1과 비례, 뒤에 2와 반비례) & R2 ↑
C21 ↓ -> P(w2) ↓ & P(w1) ↑ (앞에 1과 비례, 뒤에 2와 반비례) & R2 ↓

위의 그림에서 theta(=T)가 커지면 (theta-b로 증가) R1의 영역이 작아짐
아래식도 같이 참고

Summary

위의 값을 통합함수로 써서 분별함수로 다시 표현함

분별함수와 risk함수는 반비례하는 관계 (ji가 반대로 된거 참고)
q가 최소가 된다는 것은 사후 확률이 최대가 된다는 것
( q2 ↓ = c12 ↓ & P(w1) ↓ & P(w2) ↑ 아래식 참고 )
qi = ∑CjiP(x|wj)P(wj)
= 1 - CiiP(X|wi)P(wi)

분별함수사용의 장점
1. 여러 분류기를 하나의 틀로 표현
2. 주로 로그를 씌워서 간단히 표현할 수 있음(자연로그)
f(.)가 단조 증가라면 p(x|ωi) P(ωi)대신 gi(x)=f(p(x|ωi) P(ωi)) 사용하여도 같은 결과
- f(.)로 log 함수를 주로 사용
- log는 곱셈을 덧셈으로 바꾸어 주므로 수식 전개에 유리함