직접적으로 policy에 대해 critic하여 value-network의 가치를 상승시키는 목적으로
policy-based와 value-based를 합친것임

– The actor network
• A policy network
• Finds an optimal policy
– The critic network
• A value network (estimates state value)
• Evaluates the policy produced by the actor network
: 어떤 state의 가치를 판단해줌
Policy gradient에서의 value network와의 비교
- Policy gradient: value network의 목적은 state value를 사용하여 policy gradient의
산포를 감소시키는 역할을 함
- Actor-critic method:
critic network의 목적은 1) gradient의 산포를 줄이고, 2) 더 개선된 policy를 생성하는 것임
actor network)
Policy gradient with baseline과 Actor-Critic method의 목적함수 비교
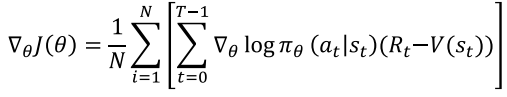

차이점은 Policy gradient with baseline에서는 episode 끝까지 간 뒤,
얻을 수 있는 Return 값을 사용했다면, Actor-Critic method에서는 아래와같이
Return을 추정하여 사용함 (그러므로 시그마도 사라짐)
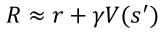
Critic network)
Loss fucntion (MSE사용)
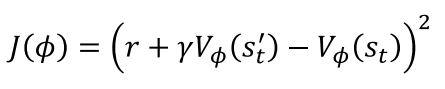
원래 노란색 부분은 Policy gradient에서는 R(t)인데,
V로 바꾸면서 추정값을 사용하는 것이 차이점임
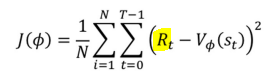
코드 설명 - Cart pole
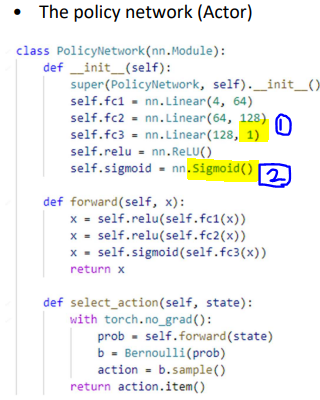
1) output 값이 1인 이유:
Cart pole에서 action은 2가지 이지만, 확률로 결정할 것이기 때문에
(베르누이분포에 따라) 한가지 action의 대한 확률값을 정하고
1에서 빼주면 됨
2) softmax가 아닌 sigmoid를 사용한 이유:
확률의 결과가 나와야 되므로 0~1사이의 값을 갖기만 하면 됨

value network에서의 output이 의미하는 것은?
: input state에 해당하는 value를 의미함
아래코드에서, k=0의 의미는 32번(batch size)만큼 반복한 뒤, 초기화 함으로써
policy gradient with baseline과 같이 episode끝까지 가서 return값을 계산하는 방식을
따르지 않는다는 것을 알 수 있음
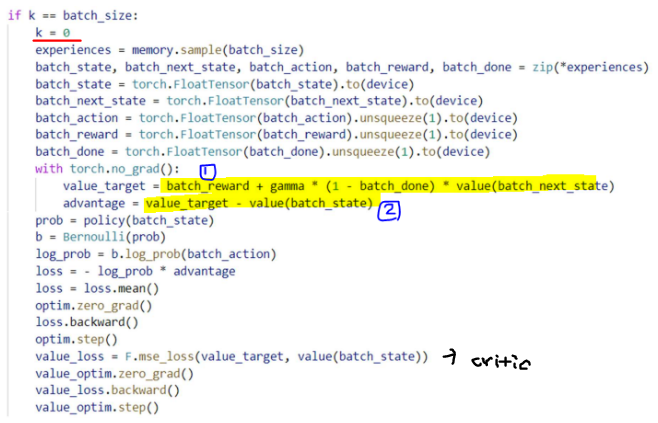
Actor network에서의 policy gradient 계산
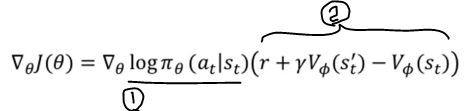
검은색 1) log-prob
검은색 2) advantage
critic network에서의 loss 계산
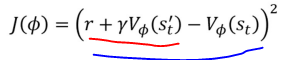
빨간색 밑줄: value target (코드에서의 1번)
파란색 밑줄: advantage (코드에서의 2번)
Actor-Critic에는 아래와 같은 종류가 있음
1. A2C: Q function과 the value function의 차이값을 function으로 사용함
2. A3C: A2C의 분산화 버전 ( Asynchronous하게 병렬연산함) - 생략
3. DDPG
4. TD3
5. SAC
1. Advantage Actor-Critic (A2C)
Q function과 the value function의 차이값을 function으로 사용함

아래 식으로 위의 식이 유도됨

** 참고) Q(s,a): "s" state에서 "a" action을 취해 episode 끝까지 갔을 때 얻는 return이라는 뜻임
즉, R = Q(s,a) : 둘이 유사함
2. Asynchronous Advantage Actor-Critic (A3C)

사용 예) 병원과 같이 개인정보를 다루는 곳은 학습을 위해 gradient와 parameter만 공유함
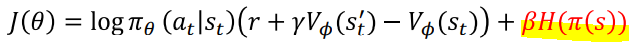
마지막 term(H)이 entropy인데 entropy가 높으면 좋음 (Beta는 상수임)
왜냐하면, work마다 다른 gradient를 얻어야지 성능이 좋아지기 때문에
불확실성(랜덤성)을 높여야지 다양한 측면에서 학습을 할 수 있음
(** 불확성실이 높으면 entropy가 높아짐)
3. DDPG (Deep Deterministic Policy Gradient)
DDPG는 action space가 continuous한 환경에서 사용됨
policy gradient인데, deterministic policy를 사용하는것( instead of a stochastic policy )
• Actor
– a policy network
– tries to learn the mapping between the state and the action
– given the state as an input, the actor outputs an action (which is a value in the continuous action space)
– uses the policy gradient method to learn the optimal policy that achieves the maximum return
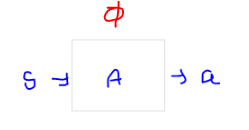
- input: State
- output: action
** Actor의 결과(output)가 Critic의 action으로 들어감
• Critic
– a value network (Q값이 높으면 좋은 action이라고 판단함)
– evaluates the action produced by the actor network using DQN

- input: State, action
- output: Q(s,a)
** 표기 참고 deterministic vs. stochastic
action = μ(s) : deterministic
action = ㅠ(s) : stochastic
Critic network 목적함수



Critic network : Target & main
목적함수에서 하나의 network를 target과 training을 같이 사용하는 이슈가 있음
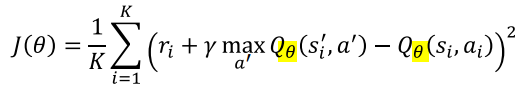
그러므로 두가지 critic network를 사용함
1. main critic network: updates parameters using gradient descent.
2. target critic network: main critic network에서 나온 parameter를 copy함
replacement = training한 결과를 target으로 엎어치는 것
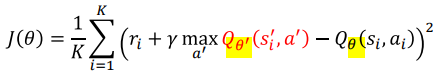
그 결과, target critic network는 theta'으로 표현
** soft replacement: main critic network의 값을 그대로 copy해오는 것이 아니라,
작은 비율만큼 copy해 오는 것

Actor network(target & main) 목적함수
DDPG는 deterministic policy를 사용하므로, 매번 같은 action을 취함 (exploration-exploitation dilemma)
→(noise 추가의 이유) noise를 추가해서(Gaussian random noise) exploration을 강제화함
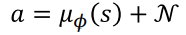
actor network의 목적함수는 아래와 같음
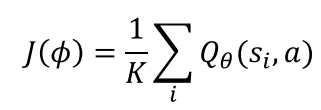
Actor network는 Critic network의 output인 Q값을 높이는 방향으로 learning하게 됨
( Critic의 output이 중요하므로 critic network의 역할이 중요)
** Critic network와 동일하게 target & main network에서 soft replacement를 사용함
DDPG를 구성하는 4개의 neural network
- The main critic network
- The target critic network
- The main actor network
- The target actor network
Pendulum Swingup 설명
1. 3개의 state
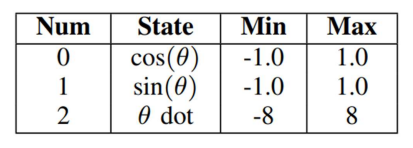
θ dot: velocity (이동하는 속도)
2. action은 -2~2값을 가짐

tanh는 -1~1까지의 범위를 취하는데 action은 -2~2를 취하므로
곱하기 2를 해줌
(값이 클수록 미는 힘이 큰 것임)
3. Reward: 안정감있게 가만히 서있을 때, reward가 0이며 가장 높은 reward 값임

θ의미 : 기울어진 정도 (똑바로 서있을 때, θ = 0 )
많이 기울어질 수록 θ값은 커짐
theta_dt의미 ( = θ derivative): θ 미분 값으로 흔들리는 속도를 의미함
input: state 차원3개, action 1개

코드 설명 내용

critic network에서 input이 4개인 이유:
state 3개와 action1개가 들어오기 때문

eval_network에만 optimizer를 해주는 이유는 무엇인가?
target_network soft replacement만 해주면 되기 때문에
gradient normalization해주는것이 clip_grad_norm임
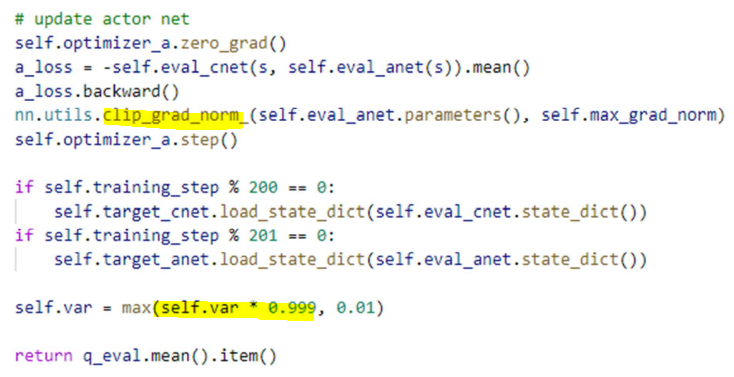
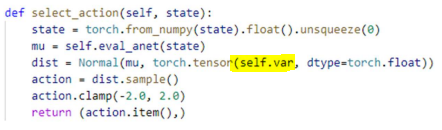
self.var에 0.999를 해주므로써 점점 작은 값을 값게 되는데,
초반에는 exploration을 많이하다가, 점점 작은 분포에서 추출하게 되므로
exploration을 줄여나간다는 의미임
'IT > 강화학습' 카테고리의 다른 글
| Twin Delayed DDPG (TD3), Soft Actor-Critic (SAC) (2) | 2022.12.06 |
|---|---|
| Multi-Armed Bandit (MAB) (0) | 2022.12.04 |
| Policy Gradient Methods (0) | 2022.11.15 |
| Deep Q Network (0) | 2022.11.01 |
| Temporal Difference Learning (0) | 2022.10.25 |