시간성 특성이 없는 데이터

축을 바꿔도 문제의 본질이 바뀌지 않음

하지만 2를 그리는 순서를 바꾸면 2를 알아볼 수가 없음
1. 마코프 모델 (Markov Model)
시간 t에서의 관측은 가장 최근 r개 관측에만 의존한다는 가정 하의 확률 추론

2차 이상에서는 추정할 매개 변수가 많아 현실적인 문제 발생
주로 1차 마코프 체인만 사용
상태전이: state transition probability matrix
1. 상태전이 확률 행렬
2. 상태전이도

상태전이확률행렬은 아래와 같이 표현됨

1차 MM에서 관측벡터 O의 확률 구하기

예시1)

예시2)


0차에서의 MM

2차에서의 MM

MM의 단점
1. 보다 복잡한 현상이나 과정에 대한 모델링 능력의 한계
해결책: 모델의 용량을 키우기 위해, 상태를 감추다.
2. 차수에 따라 기하급수적으로 모델 크기가 증가함 (2차 마코프모델)
→ r차에서 mr (m-1) 개의 매개 변수 (각 행의 합은 1이므로 하나는 몰라도 1에서 빼주면 됨)
2. 은닉마코프 모델 (Hidden Markov Model)
HMM의 장점
상태를 감추기 때문에,
차수를 미리 고정하지 않고 모델 자체가 확률 프로세스에 따라 적응적으로 정함
따라서 아무리 먼 과거의 관측도 현재에 영향을 미침
이런 뛰어난 능력에도 불구하고 모델 크기는 감당할 정도임
HMM와 MM의 차이점
마코프 모델에서는 상태를 나타내는 노드에 관측 (비, 해, 구름) 그 자체가 들어있다.
즉 상태를 볼 수 있다.
HMM에서는 상태를 볼 수 없다. 즉 상태가 은닉된다.

은닉 마코프 모델에서는 관측값들이 확률값로 표현됨
예시) 예를 들어, "해→해→비→구름이 관측되었다"고 한다면
마코프 모델
- 그것은 상태 s3→s3→s1→ s2 에서 관측한 것이다.
은닉 마코프 모델
- 모든 상태에서 {비,해,구름}이 관측 가능하므로 s3→s3→s1→s2 일 수도 있고
s1→s2→s3→s1 일 수도 있다. 가능한 경우는 몇 가지 일까?
HMM 아키텍처

응용의 특성에 따라 적절한 아키텍처 선택 중요
예를 들어 음성 인식은 좌우 모델이 적당함. 왜?
날씨와 같이 반복적으로 나타나는 경우는 Erogodic이 더 적절함
음성인식은 시계열이 있으므로 좌우모델이 적절함
세가지 매개변수 Ө=(A,B,π)
1. 상태전이 확률행렬 A=|aij|
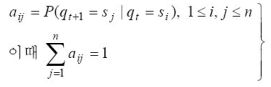
2. 관측행렬 B=|b(vk)|

3. 초기확률벡터 ㅠ=|ㅠi|

세 가지 고려해야할 문제
1. 평가: 모델 Θ가 주어진 상황에서, 관측벡터 O를 얻었을때 P(O| Θ)는?
→ 관측값의 발생확률을 보는 것임
→ 동적 프로그래밍 사용
2. 디코딩: 모델 Θ가 주어진 상황에서, 관측벡터 O를 얻었을때 최적의 상태열은?
→ 동적 프로그래밍 이용 (Viterbi 알고리즘)
3. 학습: 훈련집합 X={O1 ,..,ON }이 주어져 있을때 HMM의 매개 변수 Θ는?
→ (Θ가 HMM자체를 의미함)
→ EM 알고리즘 (Baum-Welch 알고리즘)
1. 평가: 아래 예제 풀어보기
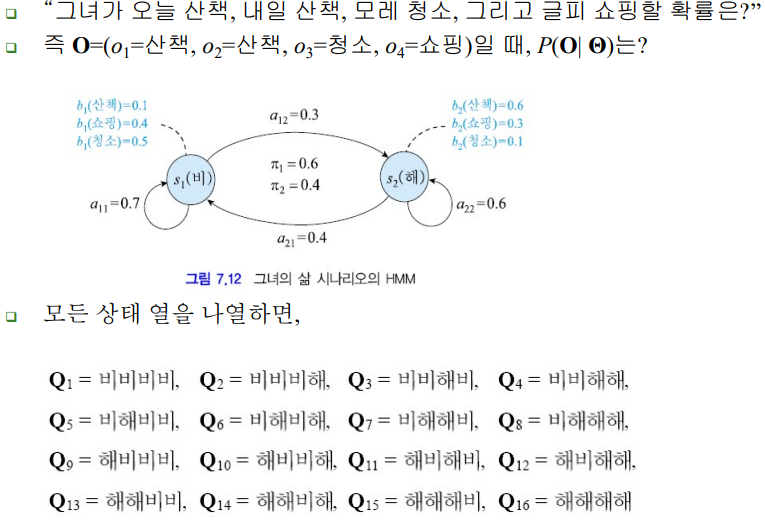
Q13이 가장 큰 값인 이유는, 비비의 transition prob도 a11=0.7로 가장크고,
비올때 쇼핑할 확률도 해떴을 때 쇼핑할 확률보다 크기때문임
HMM의 복잡도
위의 예제는 2^4인데, O의 길이가 T라면 복잡도는 더 길어짐
→ 해결책: 동적 프로그래밍에 의한 중복 계산 제거
상태의 수가 n이고 관측 열 O의 길이가 T라면 복잡도는

동적프로그래밍

즉, 바로 이전 값(t-1)까지는 같으니 그걸 활용한다는 것
(아래 수식 참고)


밑줄 친 파란색을 참고하면 loof를 도는 것, 즉 복잡도는 아래와 같음

2. 디코딩:
예를 들어, O=(o1=산책, o2=산책, o3=청소, o4=쇼핑)이었다면,
산책은 s1 보다 s2가 확률이 높으므로 s2 , 청소는 s1 이 확률이 높으므로 s1 ,
쇼핑은 s1 이 확률이 높으므로s1을 취함.
즉 O의 최적 상태열은 Q= s2 s2 s1 s1 =‘해해비비’로 함
합리적인가?
합리적이지 않음. 초기확률과 전이확률을 고려하지않고 관측값만 고려했으므로
평가 문제와 비슷하게 계산
모든 Q에 대해 계산하고 (그것을 더하는 대신) 그것 중 가장 큰 것을 취함


Viterbi 알고리즘
1. 전방계산 (매 단계에서 최적 경로 기록)
2. 최적 경로 역추적


3. 학습:
학습 문제란?
관측 벡터O가 주어져 있을때 HMM의 매개 변수 Θ는?
→ 즉 O의 발생 확률을 최대로 하는 Θ를 찾는 문제
(평가와 디코딩의 반대 작업)


Baum-Welch알고리즘(EM알고리즘) 특징
수렴한다.
greedy 알고리즘이므로 전역 최적점을 보장X
HMM추가 설명
1. HMM의 출력은 확률. 큰 장점이다.

2. 샘플 생성 능력이 있다. HMM은 생성generative 모델이다.
3. HMM을 예측 목적으로 사용할 수 있다.
4. HMM을 분류기로 사용할 수 있다.
5. 적절한 아키텍처를 선택해야 한다.
그녀의 삶은 어떤 모델? (Ergodic)
음성 인식은 어떤 모델? (Left-right)
6. 상태의 개수를 적절히 해야 한다
'IT > 패턴인식' 카테고리의 다른 글
| 특징추출2 - PCA, LDA (0) | 2022.12.08 |
|---|---|
| 특징추출 - 퓨리에 변환 (0) | 2022.12.07 |
| 질적 분류 (0) | 2022.11.24 |
| 비선형 SVM (0) | 2022.11.17 |
| 선형 SVM (1) | 2022.11.09 |