단어를 구분하는 단위
⚫ 형태소(morpheme): 의미를 가지는 언어 단위 중 가장 작은 언어단위이다.
그러므로 형태소는 더 쪼개면 전 혀 의미가 없어지거나 또는 이전의 의미와 관련되는 의미가 없어지는 문법 단위
⁻ 예) 내일 오후 세시에 학교 가자
⁎ 내일/오후/세/시/에/학교/가/자
⚫ 어절: 어절은 띄어쓰기로 나누어지는 언어 단위이다.
⚫ 음절(syllable): 화자와 청자가 한 뭉치로 생각하는 발화의 단위.
음소보다 크고 낱말보다 작 다. 음절은 자음과 모음 또는 단독 모음으로 구성된다.
예) 내/일/오/후/세/시/에/학/교/가/자
언어모델
단어 별로 decomposition을 한 후,
history(𝑤𝑘−,1 𝑤𝑘−2, … ,𝑤0)로 부터 다음 단어(𝑤𝑘)를 예측함

단, 문장의 길이가 길어질 수록 메모리를 많이사용
→ history의 길이 제한 = n-gram
각 단어들은 컴퓨터 내부에서 어휘에 대한 index로 표현
가나다 순으로 정렬후 index를 부여함
⁻ ‘가자’: 12,844번째 단어
⁻ ‘내일’: 24,882번째 단어
⁻ ‘세시에’: 35,493번째 단어
⁻ ‘오후’: 69,864번째 단어
⁻ ‘학교’: 95,867번째 단어
→ ‘내일/오후/세시에/학교/가자’는 아래와 같이 index의 열로 표현된다.
⁻ 24,882/69,864/35,493/95,867/12,844
→ 대소비교가 의미없음 그냥 index이므로
n-gram 모델
⁻ Unigram : 현재 한 단어만 반영
⁻ Bigram : 바로 앞 단어까지 반영
⁻ Trigram : 바로 앞 두 단어까지 반영
Estimating n-Grams From Counts
Expectation Maximization에 사용하여 𝑃( 𝑤𝑖 | 𝑤𝑖−2, 𝑤𝑖−1) 를 계산
아래의 문제를 풀때 EM알고리즘을 사용하여
이미 학습자료로 주어진 파란색을 가지고 테스트를 하기 때문에,
성능이 좋다고 할 수 없음

N-gram 언어모델의 장점
⁻ 통계적 모델로써 계산의 간편함
⁻ 대용량 학습 자료를 이용하여 쉽게 모델 생성이 가능함
N-gram 언어모델의 단점
⁻ N의 제약으로 인하여 longer history에 대한 정보를 표현하지 못함
n-gram 언어 모델 ARPA format
log10(P)를 활용함

언어모델에서의 메모리문제
언어모델에서의 학습 자료의 부족
→ unseen tuple에 대해서 확률값이 필요함
해결책1) Discounting & Smoothing
해결책2) Backing-off
Discounting & Smoothing
나온 카운트를 누적하여 총합으로 나눔
→ 역시 발생확률이 적은 계속 0이 되어 문제해결이 잘 안됨
→ Discounting & Smoothing는 발생확률이 적은거에 많은 것의 일부를 떼어주는 것임
(dr을 곱해주는 수식 참고)

Discounting & Smoothing 알고리즘 종류
◼ Laplace smoothing (Add-one smoothing)
◼ Add-k smoothing
◼ Good Turing smoothing
Laplace Smoothing
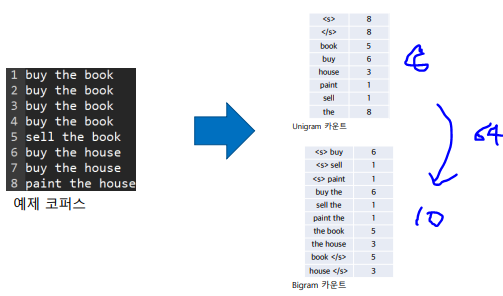
총 8개의 unigram이므로 bigram의 경우 8*8=64개가 존재할 수 있지만
실제는 10개의 bigram만 나옴
54개는??
→ Laplace에서는 무조건 0인 조합에 대해서 1을 제공함 (= add1 smoothing)
→ 단점: 1번 seen한 것과 의미차이가 없어짐
→ 1을 더하는 것에 대한 수학적 근거가 없어 성능이 좋지 못함
Laplace Smoothing

7을 더하는 이유는 총 unigram카운트에서 앞에 단어가 하나 나온 뒤,
8개의 단어가 그 뒤에 나올 수 있으나,
실제 문장 시작을 뜻하는 <s>는 제외하므로 7임
Good turing smoothing

전체 unigram count(총 단어수)가 14585이므로 bigram은 14585의 제곱값이 나와야 되지만
실제 seen count에 대해서 위의 수식과 같이 계산함
(위에는 unseen에 대한 것이고 아래 2줄은 seen에 대한 것임)
UNSEEN 수식: (r+1)*(Nr+1)/Nr
→ unseen tuple에 대해서 확률값이 필요함
◼ Good turing smoothing의 문제점
- 모든 카운트들을 대체 할 수 없다 (ex. Nr+1 = 0 인 경우 nr은 추정할 수 없다)
Back-Off 언어모델
적절한 n-gram언어모델 생성확률 추정이 어려운 경우,
모델링 파워는 낮 지만 적은 양의 코퍼스로부터 적절한 확률추정이 가능한
(n-1)-gram을 사용하여 추정함.
> tri-gram에서 추정하는 모델의 추정이 어려운경우
2-gram으로 모델링 파워가 낮지만 안정적인 모델로 추정하는 것이라고 생각하면 됨
Katz back-off
Bigram의 경우) 집합 A와 B를 정의
A: 관측된 집합, B: 관측되지 않은 집합
𝐴 {𝑤 | 𝑐(𝑤𝑖−1 𝑤) > 0 }
B {𝑤 | 𝑐(𝑤𝑖−1 𝑤) = 0 }

1-gram: sentence begin/end포함 총 5개임
Cay: log(2/8) = 0.60206임
분모가 8인 이유
<s> K Cay </s> 4개
<s> K Ache </s> 4개
<s> Cay </s> 3개 로 총 11개 이지만
sentence begin은 의미가 없으므로 11-3을 해서 8이 됨

N1=4, N2=2
unseen계산을 위해 n2/n3는 불가능하므로 n1/n2

Text Corpora Normalization
◼ 코퍼스는 사용하기 전에 ‘정규화’ 되어야 함.
- 사용할 수 없는 부분들은(예 : 표와 같은) 폐기되어야 하고, 데이터는 표준형식으로 저장 해야함.
- 문장들은 개별적으로 태그를 지정하며, 숫자 / 날짜는 발음에 따라 처리해야함.
(2023년은 이천이십삼년이고 이공이삼년이 아님)
언어 모델 평가척도(Perplexity)
LogProb(LP)는 각 단어 별 로그 n-gram생성확률의 산술 평균으로 정의한다.

◼ log(x) 함수는 x가 0<x<1인 경우 음수 값을 가진다.
그러므로, –1을 곱하여 LP의 값이 양수로 바꾸어 줌
(작은 값이 좋음)
'IT > 음성인식' 카테고리의 다른 글
| Connectionist Temporal Classification (0) | 2023.06.14 |
|---|---|
| WFST Decoder (0) | 2023.06.07 |
| 음향모델 (0) | 2023.05.03 |
| Multi-head attention (0) | 2023.05.03 |
| Attention의 Q, K, V와 Transformer (0) | 2023.04.12 |