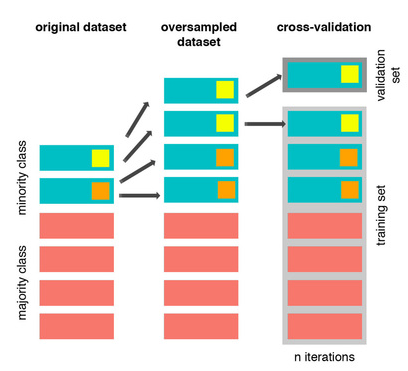
기본적으로 dummy classifier는 모델 성능을 비교할 때, base line을 명시해 줌으로써 어느 정도의 성능이 나오는지 비교하기 위해 사용합니다. DummyClassifier 라이브러리를 import 하기 전에, 우선 설명력을 쉽게 print할 수 있는 코드를 먼저 함수로 정의해 볼게요. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from sklearn.model_selection import cross_val_score def cv_recall(model, x, y): scores = cross_val_score(model, x, y, cv=5, scoring='recall'); scores #print("Mean:..