
부류내 분산은 작고 부류간 분산은 크게 해줄수록 좋은 특징 벡터
즉, Sb/Sw 값이 큰게 좋은 것임
분별력을 측정하는 3가지 방법
1. 다이버전스
2. 훈련 샘플의 거리
3. 분류기 성능
KL 다이버전스

분별력이 큰 경우는 (b) 경우임

- 두 분포가 완전히 겹치면 위의 값을 1을 가짐
두 분포가 같다면(유사하다면) P(k)=Q(k)이므로 sum(P(k)) = 1이 됨
- KL 다이버전스는 거리개념과 유사하므로,
값이 클수록 분류가 잘 됨
훈련 샘플의 거리 구하는 방법
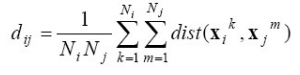
[훈련 샘플의 거리 구하는 예시]


분류기로서의 SVM
장점: 분류기에 딱 맞는 특징벡터를 찾아낼 수 있음
단점: 분류기 훈련시 계산시간이 많이 걸림
특징 선택 시, 고려해야할 것
1. 중복되는 특징벡터 사용시 단점

중복이 되므로 성능향상은 없으나, 계산시간만 많이 걸리게 됨
중복되는 특징벡터 예시)
개와 고양이를 분류하는데 눈의 개수와 같은 특징은 쓸모 없다.
특징벡터 선택 알고리즘
a. 임의 탐색 알고리즘
b. 개별 특징 평가 알고리즘

c. 전역 탐색 알고리즘(2가지 세부종류 있음)
장점: 항상 전역 최적해를 보장함
단점: 차원이 크다면 비효율 적임
* 낱낱 탐색 알고리즘: 가능성여부 상관없이 모든 해를 다 찾는 것
* 한정 분기 알고리즘: 가능성이 없으면 배제하고 나머지를 찾음
(단조성조건을 만족하는 경우에만 가능)
참고) 단조성 조건이란?
d(i)보다 d(i-1)이 더 안좋으므로 더 이상 search하지 않아도 됨
d. 순차탐색 알고리즘: 한번에 하나씩 특징을 추가해 나가는 방식
e. PTA 알고리즘: p 개의 특징을 추가하고 r 개를 제거하는 연산을 반복
(순차탐색 알고리즘의 반복형임)
모든 순차 탐색 알고리즘은 욕심greedy 알고리즘이다.
전역 최적점이 아니라 지역 최적점에 빠질 가능성
해결책:
- 시뮬레이티드 어닐링
- 유전 알고리즘

'IT > 패턴인식' 카테고리의 다른 글
| 군집화 (0) | 2022.12.15 |
|---|---|
| 특징추출2 - PCA, LDA (0) | 2022.12.08 |
| 특징추출 - 퓨리에 변환 (0) | 2022.12.07 |
| 순차데이터의 인식 (1) | 2022.12.01 |
| 질적 분류 (0) | 2022.11.24 |